You’ve probably heard or seen words “serverless” or “FaaS” -Function as a Service- over the past few months asking yourself, “ok, is this hype or does it actually have some benefits” ?
Well, I’m going to share a feedback for our use case at my job that will illustrate why going serverless helped us achieved what was asked.
To achieve our goal we used the following products/framework/libraries:
- Symfony (PHP)
- Bref.sh
- Serverless framework
- Browsershot
- Puppeteer
- Amazon SQS
- Amazon Lambda
- Scaleway S3
My team works with PHP7, Symfony and Vue.js.
You can contribute to this article for any typos or errors you may find by submitting a pull request
The need: Generate PDF analytics reports
Here’s the user stories:
- “As a customer of the CMS, I should receive each month a PDF report containing serveral analytics for my website”
- “As a reseller of this group of customer of the CMS, I should receive each month a PDF report of each customer’s reports (containing a part of each)”
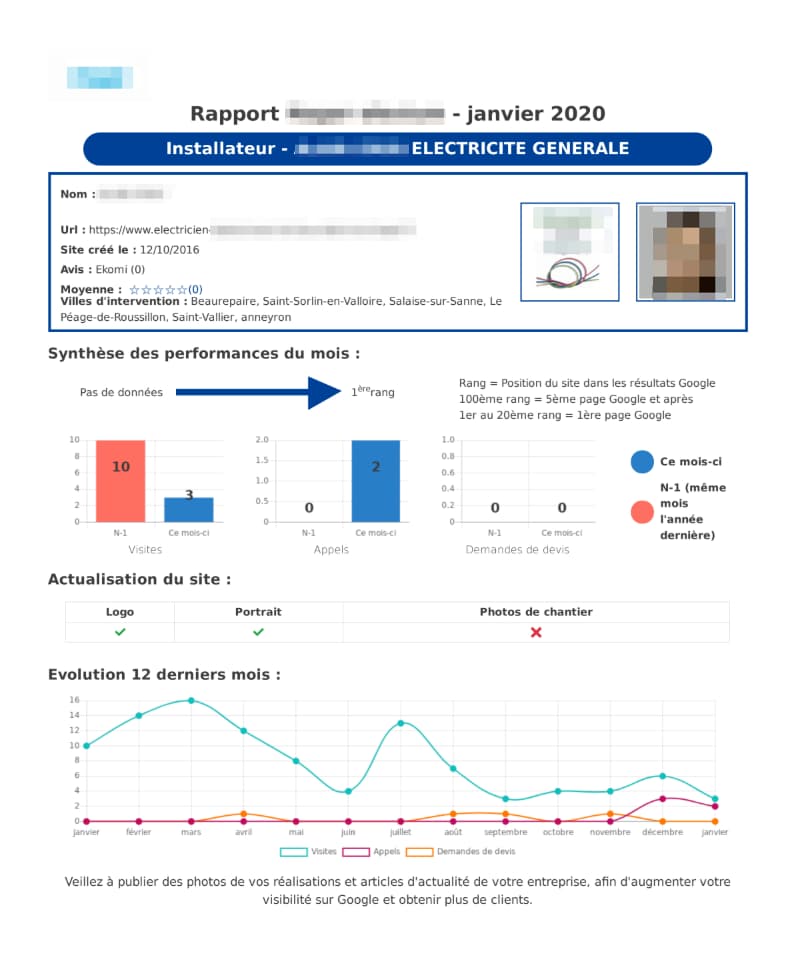
In two sentences, for our few customers with this feature, we’ll have to generate 2,000+ PDFs. Here’s what it looks like for one of the PDFs we have to generate:
 |
VPS / Dedicated server option
You could setup a cron job on one of your servers and it will take care of launching a command to generate the PDF. The main problem: it doesn’t scale.
~20 seconds (pdf generation) x 2,000 PDF = 11 hours of PDF generation
Average of generation is 2 seconds, but on a heavy PDF that contains multiple pages of multiple reports it can require up to 30 seconds.
During those 11 hours you’d need to ensure that the generation can survive that long (through app deployements, server restart etc…) and a way to monitor that the process is running, for example using Supervisor.
It would also require you to code the whole process using “defensive programming” in order to ensure the continuing function of your code under unforeseen circumstances.
Since we run a PHP app, it’s not multi-threaded, meaning, we can’t easily take advantage from all the CPU cores of our dedicated server. One of the options, if we want to achieve concurrency, is to rent more servers which we have to deploy, provision and manage.
Serverless option
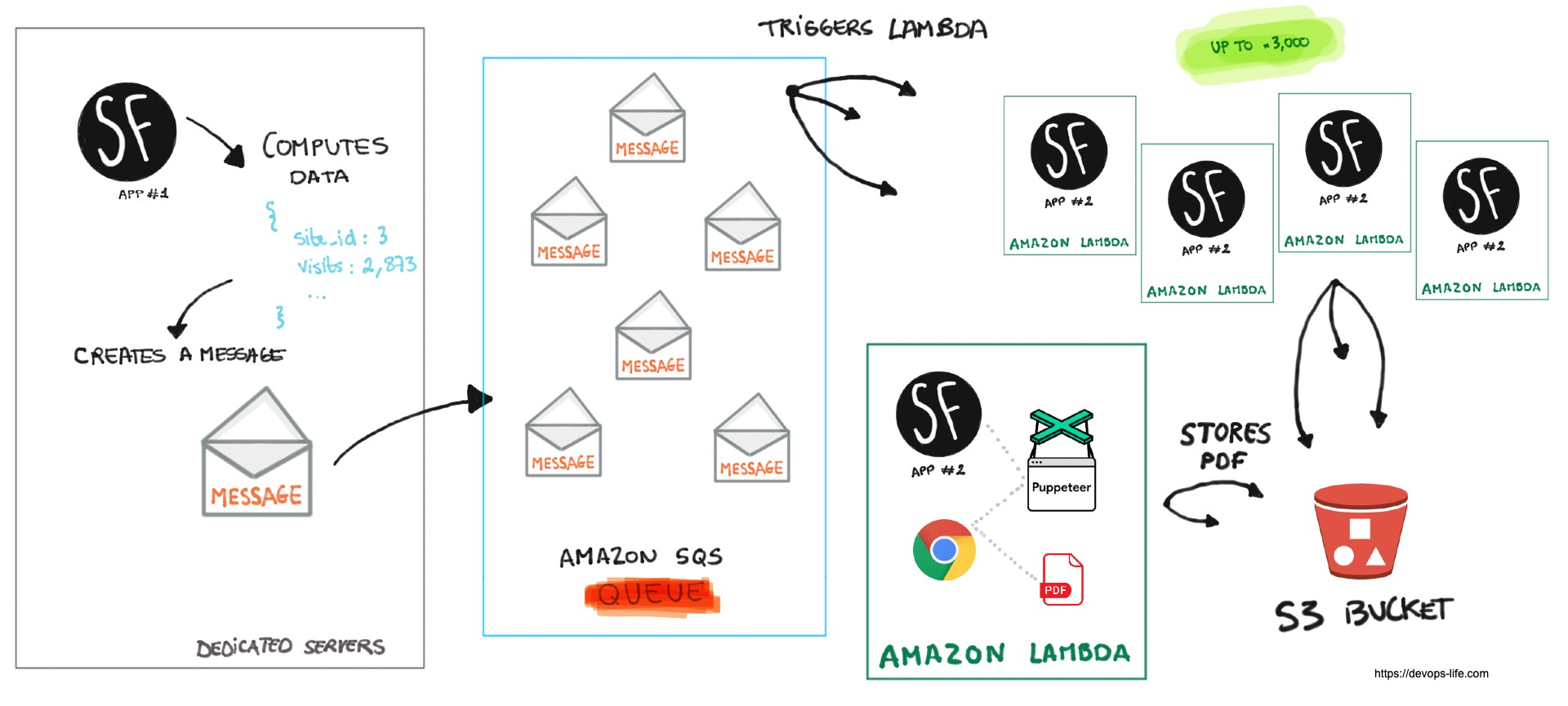
Here’s the workflow of our setup.
 |
 |
Step 1: preparing the data
Since this PDF is an aggregation of multiple external and internal data, you will want to have the data ready when you’ll generate the PDF. The CMS application (app #1, PHP/Symfony) is responsible of gathering and storing all the data that is necessary to build the PDF into a Redis instance.
Since we want to achieve scalability, you don’t want the service responsible of generating the PDF to ask via an API the data to the app #1 because it would become a bottleneck if 3,000 simultaneous lambda would send requests to your API.
Step 2: create async messages
Now that all the data is ready, the app #1 is crafting the data in a message, wrapping it inside an enveloppe using Symfony Messenger in order to send the messages to an Amazon SQS queue.
Note for Symfony users: because the messages will be read by another (Symfony) application, you must use a custom message serializer. You can read more on a RFC I opened on Symfony repository.
Step 3: store messages in a queue
As soon as the messages arrive inside an Amazon SQS queue, it triggers an action on our lambda running our code to generate PDFs.
Note: our message structure (Plain Old PHP Object) is stored in another git repository. Why ? because both app #1 and app #2 need to have this POPO, so chances that a developper would update the message structure on app #1 but not on app #2 were an unecessary risk.
Step 4: generate the PDFs
Up to 3,000 lambda instances are started, that’s some serious scalability there (in our case we limited it at 50 concurrent lambdas). Each lambda receives one message containing the data to generate 1 PDF.
Then the lambda runs our app #2 (PHP, Symfony) responsible of rendering a view inside a web page using a simple .twig templates with some javascript to render charts.
Then the code uses Browsershot, which transforms a web page to a PDF by using a headless Chrome controlled via pupetter to visit the URL that renders the .twig template which will become our PDF.
Once the PDF is generated, it’s stored in a S3 bucket.
We used Bref.sh around Symfony; It’s awesome because it provides lambda integration for your favorite PHP framework and also different PHP runtime that will run on the lambda.
All the 2,000 PDFs are generated within 2 minutes
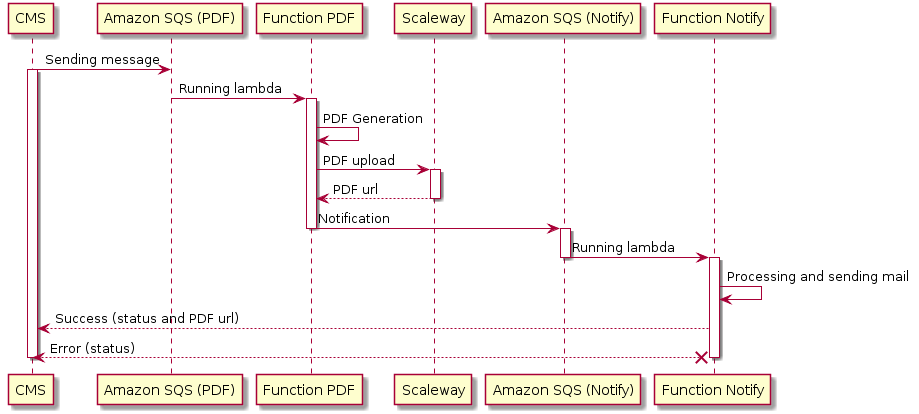
Step 5: email the PDF to the client
The architecture image is only a part of what really happens. Because once the PDF has been generated in the bucket, we generate a new Message, send it to another SQS queue, and then, this particular queue is using app #2 again (but another part of the code) to send an email to the client with the PDF attached and notify the CMS application so clients can download their PDF through the backoffice too.
Comparison
| VPS or Dedicated server | Serverless | |
|---|---|---|
| Complexity | Low | Medium |
| Cost | Expensive | Cheap |
| Scalability | Complex | Very scalable |
Conclusion
One of the main advantage of using serverless architecture is that you get billed only for the time it was required to run the code.
You also don’t have to take care of where or how it runs. You just ship code and it runs in the cloud. The cloud provider is responsible of managing the allocation of the machine resources.
In our example, using the free tier of Amazon Lambda and Amazon SQS, generating 2,000 PDFs is costing us ~$1.63 ($1.62 for SQS, $0.01 for Lambda). You can use this serverless costs calculator to get better insights.
If you think you have some part of your code that could benefit from being moved to a serverless architecture, I would advise that you start with a very simple POC so you can get familiar with these new concepts. We did that with a small portion of our code before even attempting to solve the PDF problem to better understand the full ecosystem (queuing, lambda, notification…). We now have 5 lambdas doing specific jobs (outside the PDF needs).
You can read more on this from a more technical point of view: Generate PDFs on Amazon AWS with PHP and Puppeteer, written by Hugo Alliaume, who helped a lot on this subject. It contains a lot of details, such as how we shipped chrome into the lambda.